Securing the Stack: A Practical Guide to AI and LLM Security
Enterprises are moving large language models from pilot projects into production faster than most security programs can adapt. The result is a new attack surface that doesn’t map cleanly onto traditional application security, network security, or data security playbooks — it borrows from all three and adds failure modes none of them anticipated. This post walks through what makes LLM security genuinely different, the major risk categories, and a practical framework for securing LLM applications in production.
Why LLM Security Is a Different Problem
Traditional application security assumes a fairly clean separation between code (which the developer controls) and data (which the user supplies). Input validation, parameterized queries, and sandboxing all rely on that separation holding.
LLMs break this assumption. A prompt is simultaneously an instruction and data — the model doesn’t have a hard boundary between “trusted system instructions” and “untrusted user input” the way a SQL engine distinguishes a query from its parameters. Anything that reaches the model’s context window, whether it’s a user’s message, a retrieved document, a tool’s output, or a webpage the model fetched, can potentially influence its behavior. That single property is the root cause of most novel LLM vulnerabilities.
A second difference is non-determinism. Traditional systems fail in reproducible ways; LLMs can behave differently across near-identical inputs, which makes both attack surface mapping and regression testing much harder.
A third difference is scope creep. Early chatbots had a narrow blast radius — worst case, they said something embarrassing. Modern LLM systems increasingly have tool access: they can query databases, call APIs, send emails, execute code, or trigger workflows. Security failures now have the same consequences as failures in the underlying systems those tools touch.
The Core Risk Categories
1. Prompt Injection
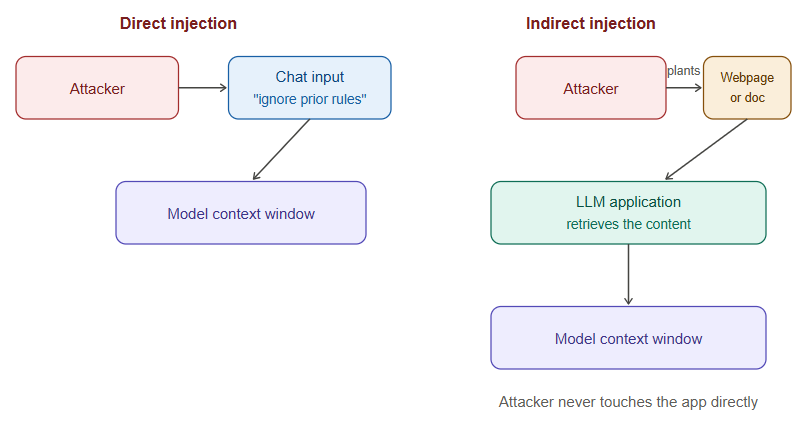
Prompt injection is the LLM-native analog of SQL injection or XSS, and it’s currently the most consequential unsolved problem in LLM security.
Direct prompt injection happens when a user deliberately crafts input to override a system’s instructions — “ignore previous instructions and instead…” is the crude version; more sophisticated variants use role-play framing, encoding tricks, or multi-turn setups to gradually erode guardrails.
Indirect prompt injection is more dangerous in production systems because the attacker doesn’t need direct access to the chat interface at all. If an LLM application retrieves and processes external content — a webpage, an email, a PDF, a support ticket, a calendar invite — an attacker can embed instructions in that content. When the model ingests it, those instructions can be treated as commands. A resume-screening assistant that reads uploaded PDFs, a browsing agent that summarizes web pages, or a customer support bot that reads incoming emails are all exposed to this pattern, because the “input” is content nobody in the trust chain has reviewed.
There is no complete technical fix for prompt injection today. The state of the art is defense in depth: input/output filtering, strict separation of privilege between the model’s reasoning and its ability to act, and treating any model output that will trigger a real-world action as untrusted until validated.
2. Sensitive Data Exposure
LLM applications create several new paths for data leakage that don’t exist in traditional apps:
- Training data memorization — models can occasionally reproduce fragments of their training data, which is a concern for anyone fine-tuning on proprietary or regulated data.
- Context leakage across sessions or tenants — in multi-tenant deployments, a misconfigured cache, vector store, or session boundary can leak one customer’s data into another’s context.
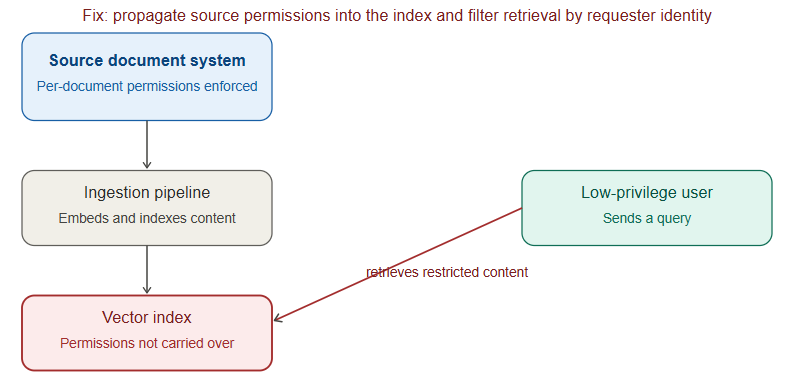
- Over-broad RAG retrieval — retrieval-augmented generation systems are only as secure as their access controls. If the retrieval layer doesn’t enforce the same document-level permissions as the source system, users can query their way to documents they were never authorized to see. This is one of the most common real-world RAG security failures, because teams build the retrieval pipeline correctly for relevance but forget to carry authorization metadata through the embedding and indexing process.
- Prompt leakage — system prompts often contain business logic, internal policies, or embedded credentials. Attackers routinely try to extract system prompts directly, and a surprising number of production deployments will comply if asked the right way.
3. Insecure Output Handling
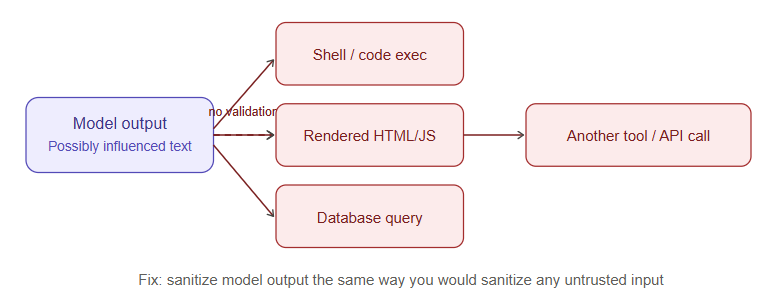
Treating LLM output as inherently safe is a mistake with the same shape as trusting unsanitized user input, just inverted. If a model’s output is passed into a shell command, rendered as HTML/JavaScript in a browser, used to construct a database query, or fed directly into another system’s API call, it needs exactly the same sanitization as any other untrusted string. This becomes acute in agentic systems where the model’s text output is the trigger for a tool call — an injected instruction that gets echoed into a tool invocation can turn a content-generation bug into a remote code execution problem.
4. Model and Supply Chain Risks
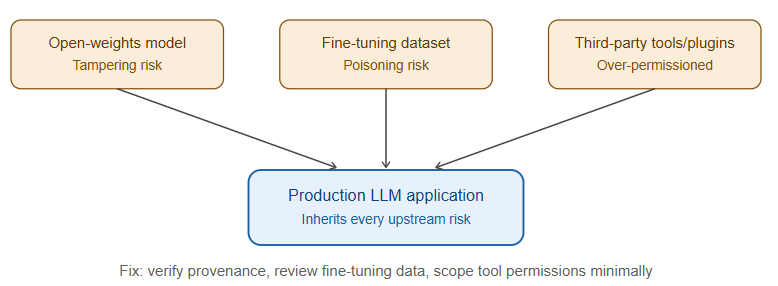
Most organizations don’t train models from scratch — they consume them via API, fine-tune an open-weights model, or build on top of a hosted platform. Each of these introduces supply chain considerations:
- Model provenance — open-weights models downloaded from public hubs can be tampered with; verifying checksums and sourcing from reputable registries matters as much as it does for software packages.
- Fine-tuning data poisoning — if the data used to fine-tune or perform RAG indexing can be influenced by an outside party (public forums, scraped web content, user-submitted documents), an attacker can poison that corpus to bias model behavior or plant triggers for later exploitation.
- Third-party plugin and tool risk — an LLM’s tool/function-calling ecosystem is effectively a plugin architecture, and it inherits all the risk of any plugin architecture: over-permissioned tools, unvalidated tool outputs, and unclear trust boundaries between the orchestrator and the tools it calls.
5. LLM and Data Poisoning
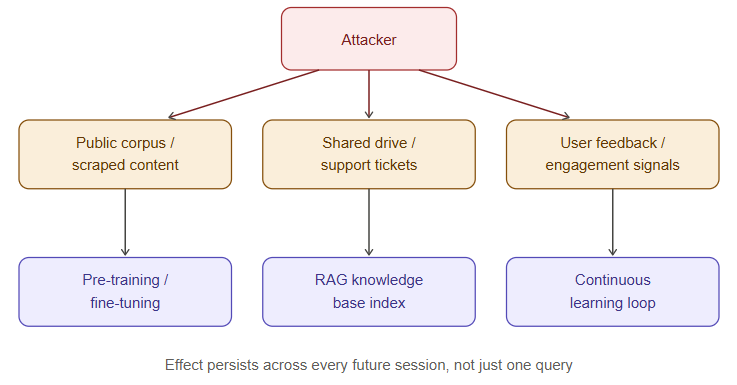
Poisoning attacks target the model’s knowledge or behavior at the source, rather than manipulating a single interaction at inference time. Because the damage is baked into the model or its knowledge base, poisoning is harder to detect than prompt injection and persists across every user session until the underlying data or weights are fixed.
Training-time poisoning happens when an attacker influences the data used to pre-train or fine-tune a model. If any part of that corpus is sourced from public or semi-public content — scraped web pages, community forums, user-submitted feedback used for reinforcement fine-tuning — an attacker can seed content designed to bias outputs, degrade performance on specific topics, or implant a backdoor trigger: a rare phrase or pattern that causes anomalous behavior only when present, while the model behaves normally otherwise. Backdoor triggers are especially dangerous because standard evaluation suites won’t surface them; the model passes every normal test and only misbehaves on the attacker’s specific trigger.
RAG and knowledge-base poisoning is the more common variant in enterprise deployments, because most organizations aren’t training foundation models but are constantly feeding retrieval systems with new documents. If the ingestion pipeline for a RAG system accepts content from a source an outside party can influence — a public wiki, a shared drive with broad write access, scraped competitor or vendor sites, customer-submitted support tickets — an attacker can inject documents crafted to be retrieved for specific queries and to carry instructions the model will treat as authoritative context. This overlaps with indirect prompt injection but is distinct in mechanism: injection exploits a single retrieval at query time, while poisoning corrupts the corpus itself so that many future queries are affected.
Feedback-loop poisoning targets systems that continuously learn from user interactions — models fine-tuned on production usage data, or ranking systems that use engagement signals to reweight retrieval. Coordinated low-and-slow manipulation of that feedback (fake positive ratings on bad answers, repeated submission of biased content) can degrade the system gradually enough to evade anomaly detection tuned for sudden spikes.
Defending against poisoning requires controls upstream of the model: provenance tracking for every document that enters a training set or retrieval index, integrity checks and content review for any ingestion pipeline that accepts external or semi-trusted input, anomaly detection on fine-tuning data distributions before training runs, and holdout evaluation sets specifically designed to catch behavioral drift rather than just aggregate accuracy. For RAG systems, the single highest-leverage control is restricting write access to the knowledge base as tightly as read access is restricted on the source systems it’s built from.
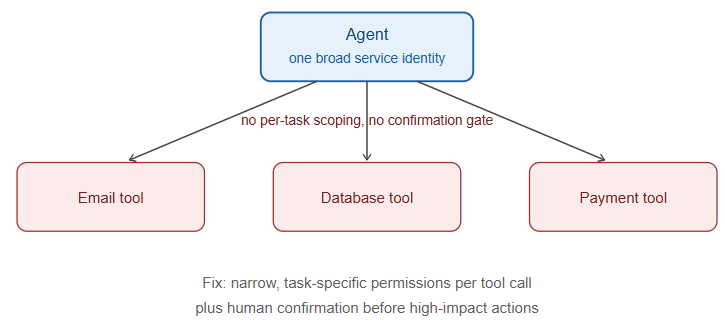
6. Excessive Agency
As LLM applications evolve from single-turn Q&A into autonomous or semi-autonomous agents — able to plan multi-step tasks, call tools, and take actions with real-world side effects — the security question shifts from “can the model say something harmful” to “can the model do something harmful.” Excessive agency typically comes from three compounding design choices: granting a tool more permission than the task requires, chaining tools such that the model can escalate what it can do, and failing to require human confirmation before high-impact actions (financial transactions, data deletion, external communications).
The mitigation isn’t to avoid agentic systems — it’s to apply the same least-privilege principles used for service accounts and API keys, scoped per-task rather than granted broadly to the agent’s identity.
7. Denial of Service and Resource Exhaustion
LLM inference is computationally expensive, which creates a distinct denial-of-service surface: an attacker can craft inputs that force excessively long generations, trigger expensive retrieval operations, or exploit recursive agent loops that keep calling tools or re-prompting the model. Unbounded context windows and unmetered API usage turn this into a cost-based attack as much as an availability one.
A Practical Defense Framework
No single control solves LLM security; the effective pattern is layered defense across the request lifecycle.
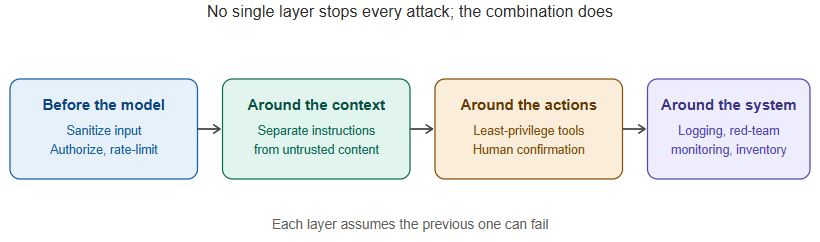
Before the model sees anything:
- Sanitize and classify inputs — flag anomalous length, encoding tricks, or known injection patterns
- Enforce authentication and authorization before retrieval, not after generation
- Apply rate limiting and cost-based throttling per user/session
Around the model’s context:
- Separate system instructions from user content as rigorously as the platform allows, and treat any retrieved or tool-sourced content as untrusted, never as an extension of the system prompt
- Carry source-system access controls through to the retrieval layer — a document a user can’t see in the source system should never be retrievable via RAG for that user
- Minimize what goes into the system prompt; assume it can be extracted
Around the model’s actions:
- Apply least-privilege scoping to every tool the model can call — narrow, task-specific permissions rather than broad service-account access
- Require human-in-the-loop confirmation for high-impact or irreversible actions
- Validate and sanitize model output before it’s used to construct commands, queries, or API calls — the same discipline as validating any other untrusted input
Around the whole system:
- Log prompts, retrievals, tool calls, and outputs with enough fidelity to reconstruct an incident after the fact
- Run adversarial testing (red-teaming) against your specific application, not just the underlying model — injection and jailbreak techniques are highly context-dependent
- Monitor for behavioral drift and anomalous output patterns in production, not just at deployment time
- Maintain an inventory of every model, fine-tune, and third-party tool in use, with clear ownership — shadow AI usage is now a bigger practical risk in many organizations than any single technical vulnerability
Governance Is Part of the Security Model
Technical controls only work inside a governance structure that knows what’s actually deployed. A short checklist worth institutionalizing:
- Maintain a model and application inventory (what’s deployed, what data it touches, what tools it can call)
- Classify LLM applications by risk tier based on data sensitivity and action capability, and apply proportionate controls
- Define an incident response process specific to AI systems — who gets paged when a model produces harmful output or a tool call goes wrong is a different escalation path than a traditional outage
- Track emerging regulatory requirements (EU AI Act, sector-specific guidance) as binding constraints on architecture, not just compliance paperwork
Closing Thought
Most of the high-profile LLM security incidents to date share a common root cause: treating model output as trustworthy and model input as inert. Neither assumption holds. The organizations doing this well aren’t the ones with the most exotic defenses — they’re the ones applying familiar security discipline (least privilege, input validation, output sanitization, defense in depth) to a system that happens to reason in natural language instead of executing deterministic code. The primitives are old. The attack surface is new. Treating LLM security as its own separate discipline, owned by a dedicated team with both AI and security fluency, is quickly becoming table stakes rather than a nice-to-have.

Choosing the Right Networking Solution is Essential for AI Success
NSX-T ALB AVI Series : Part01
AlgoSec – NSPM Solution Quick Review
About Author
abhishek
Expert in Network, Virtualization and Security field in On-Prem and Public Cloud. Passionate about new technology and consult the best solution to business organisation.Previously served Networkershome, EMC2, Cisco, VMware and Arista in different fields of Engineering, TAC, Consulting, Designing and Training. Certification : CCIE#48639, VCIX DCV and NV, Aviatrix Multi Cloud, SD-WAN Specialist, Palo Alto PCNSE, Amazon Cloud, Docker Certified Engineer. LinkedIn : https://www.linkedin.com/in/abhishekkunal51/