From Certification to Production: What the Aviatrix ACE Teaches About Multicloud Transit
Around 5 years ago I have completed the Aviatrix Certified Engineer (ACE) – Multicloud Network Associate when it was talk of the town. It’s tempting to file certifications like this under “resume line item” and move on. But this one is worth writing about, because the material addresses a failure pattern that shows up repeatedly in enterprise multicloud environments — one that’s easy to design your way into without realizing it.
A Common Setup
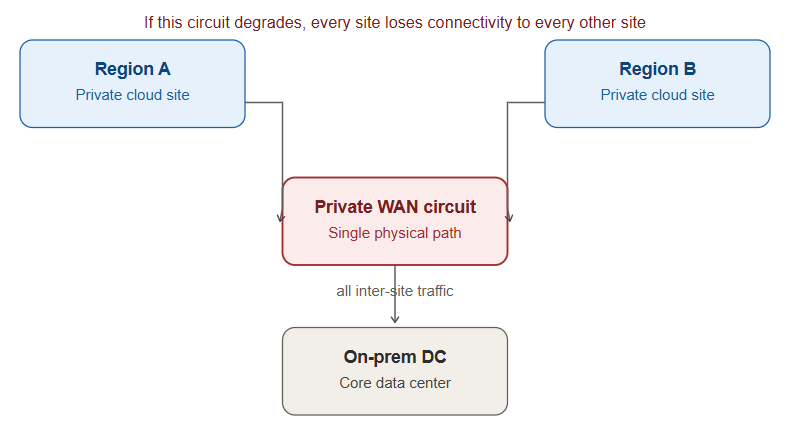
Picture a typical enterprise multi-site environment: two or more private cloud regions (say, one in the Middle East, one in Europe) connected to an on-premises data center, stitched together with a virtualization overlay like NSX-T Federation and a private WAN circuit like ExpressRoute or Direct Connect.
On paper this looks clean — a hub-and-spoke model where the overlay handles micro-segmentation and the private circuit provides the backbone between sites.
In practice, the private circuit often becomes a single point of architectural dependency. Every cross-site conversation — region-to-region, region-to-on-prem, and eventually region-to-future-region — traverses the same circuit. There’s no independent transit layer; the WAN quietly becomes the topology itself.
The Issue
The problem tends to surface when an organization needs to onboard a new region, usually for a DR expansion or capacity growth. Two things become clear almost immediately:
- Circuit bandwidth caps turn a routing change into a capacity negotiation. Adding a new site isn’t just updating a route table — it’s renegotiating a physical circuit, which can take weeks and is bounded by whatever tier of service is available in that region.
- The overlay’s span is tied to the same physical path. Any degradation or maintenance window on the private circuit doesn’t just slow things down — it takes down the only path for inter-site policy sync and traffic, because there’s no secondary transit fabric independent of the underlay.
Organizations in this position typically have redundancy in compute and storage across sites, but not in the transit layer connecting them. That distinction is easy to miss until it costs a maintenance window that can’t be taken.
The Common (Tactical) Fix
Without a dedicated multicloud transit layer, the typical workaround is tactical rather than architectural:
- Negotiate a secondary circuit on a different peering path as a failover, rather than a true parallel transit fabric
- Tighten overlay sync windows to reduce blast radius during circuit maintenance
- Document the single point of failure explicitly in the DR runbook so it’s a known risk rather than a surprise
This works, but it’s a patch on a design gap — not a fix for the gap itself. It treats the symptom (limited failover) rather than the underlying architecture problem: no cloud-native transit layer decoupled from the underlay.
Where Aviatrix Actually Fits
This is where the ACE material clarifies the gap. Aviatrix’s multicloud transit architecture is built specifically for this scenario:
- A transit fabric that sits above the underlay, meaning any single circuit becomes one of several paths rather than the path. Transit gateways in each cloud/region peer independently of the physical circuit topology.
- Encrypted, high-performance inter-region peering that doesn’t require every packet to traverse a single private circuit — so a maintenance window degrades one path, not the whole fabric.
- Centralized visibility and troubleshooting (CoPilot) across sites, replacing a lot of manual cross-checking between overlay consoles and circuit dashboards during incident response.
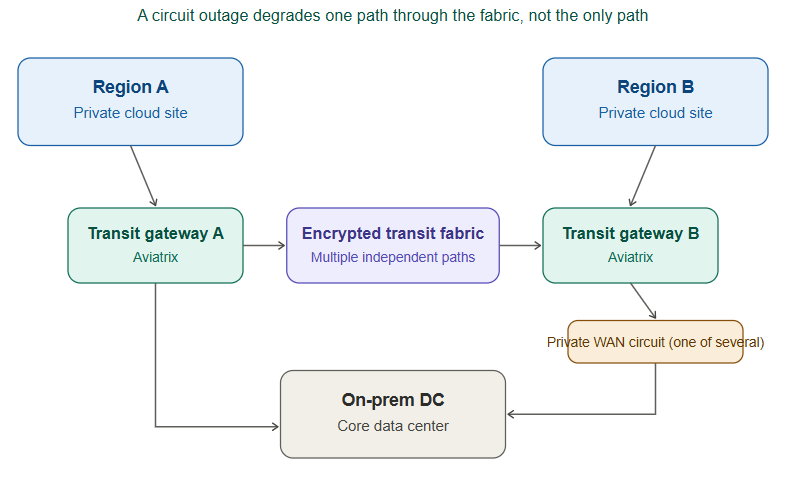
The core lesson: it’s easy to conflate “physical connectivity” with “transit architecture.” A private circuit like ExpressRoute is excellent as an underlay — it is not, by itself, a resilient multicloud transit strategy. A purpose-built transit layer like Aviatrix decouples those two concerns, which is exactly the kind of design principle that’s hard to internalize from documentation alone and much easier to internalize after an incident forces the question.
Why This Matters Beyond One Scenario
This is also why certifications like the ACE are worth more than the badge suggests. The value isn’t the exam questions — it’s that structured study forces you to formalize architectural principles that most engineers otherwise only learn ad hoc, incident by incident. Deep networking and virtualization expertise gets you most of the way there; what a multicloud-transit-focused certification adds is a clean mental model for transit as its own architectural layer, independent of whichever cloud or circuit happens to sit underneath it.
If you’re running multi-site private cloud, multi-cloud Kubernetes, or any environment where “the WAN” and “the topology” have quietly become the same thing, it’s worth asking the question before an incident forces the answer: what happens to inter-site traffic if your primary circuit goes down — not degraded, down?

Choosing the Right Networking Solution is Essential for AI Success
NSX-T ALB AVI Series : Part01

Azure Has Lost the Plot: When Feature Marketing Replaces the Promise of Easy Cloud
About Author
abhishek
Expert in Network, Virtualization and Security field in On-Prem and Public Cloud. Passionate about new technology and consult the best solution to business organisation.Previously served Networkershome, EMC2, Cisco, VMware and Arista in different fields of Engineering, TAC, Consulting, Designing and Training. Certification : CCIE#48639, VCIX DCV and NV, Aviatrix Multi Cloud, SD-WAN Specialist, Palo Alto PCNSE, Amazon Cloud, Docker Certified Engineer. LinkedIn : https://www.linkedin.com/in/abhishekkunal51/