Private LLMaaS and its Business Opportunities
Introduction
LLMaaS is one of the services which is in great demand in the market, so the organization can utilize or get any managed service company to build their AI use cases. In past few days I have used multiple public LLM providers like Claude, Openrouter , Open AI, DeepSeek, etc to develop enterprise applications and among all Openrouter Services impressed me a lot.
OpenRouter has become one of the most elegant solutions in the AI ecosystem — a single API gateway
that routes requests intelligently across 400+ LLMs from dozens of providers. For most developers
building public-facing products, it just works.
But what if your organization can’t send prompts to the internet? What if you’re dealing with financial data, healthcare records, proprietary source code, or classified documents? What if your enterprise security policy mandates air-gapped inference?
This blog walks through how to design and build a Private LLM Router — an OpenRouter-equivalent
running entirely on your own infrastructure, routing requests across locally-hosted models (vLLM, Ollama,
NVIDIA NIM, Hugging Face TGI) with the same developer ergonomics and its business opportunities.
Why Not Just Use OpenRouter?
- Data sovereignty: Prompts and completions must never leave your network perimeter
- Compliance: HIPAA, PCI-DSS, SOC2, ISO27001 — data residency requirements forbid external
API calls - Latency control: Sub-50ms routing requirements that external APIs cannot guarantee
- Model customization: Fine-tuned or domain-specific models not on any public registry
- Cost structure: Token pricing at cloud rates vs. amortized GPU hardware cost
- Air-gap requirements: Physically disconnected networks (defense, critical infrastructure)
High-Level Architecture
The private LLM router mirrors OpenRouter’s layered design but replaces every external dependency with
an on-prem or self-hosted equivalent. Here is the full stack view:
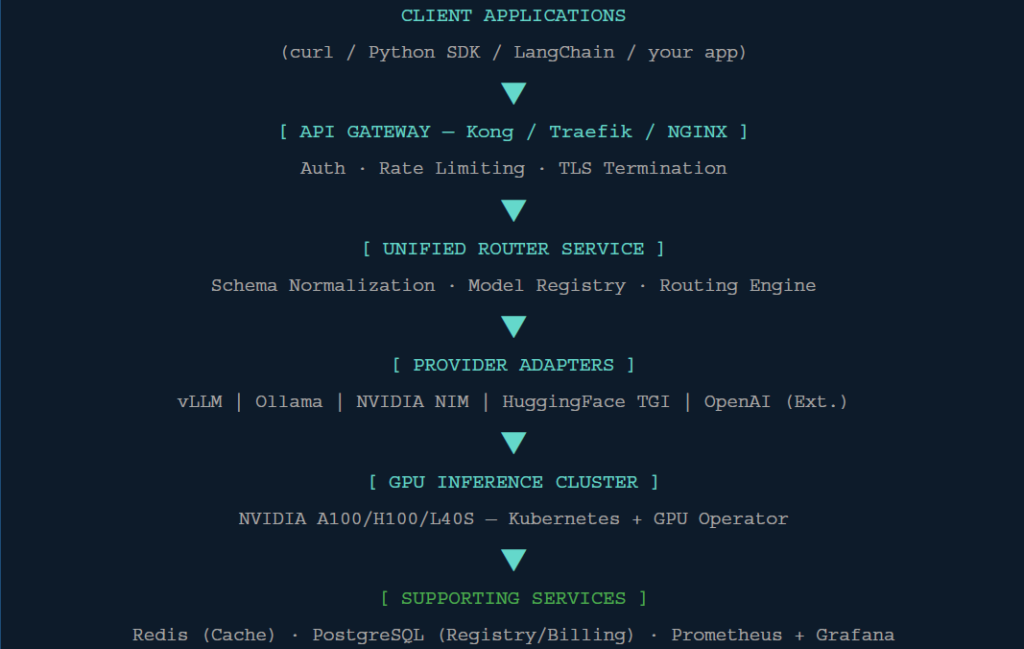
Each layer has a clear responsibility. Requests flow down through the stack and responses bubble back
up — with every hop logged, metered, and observable.
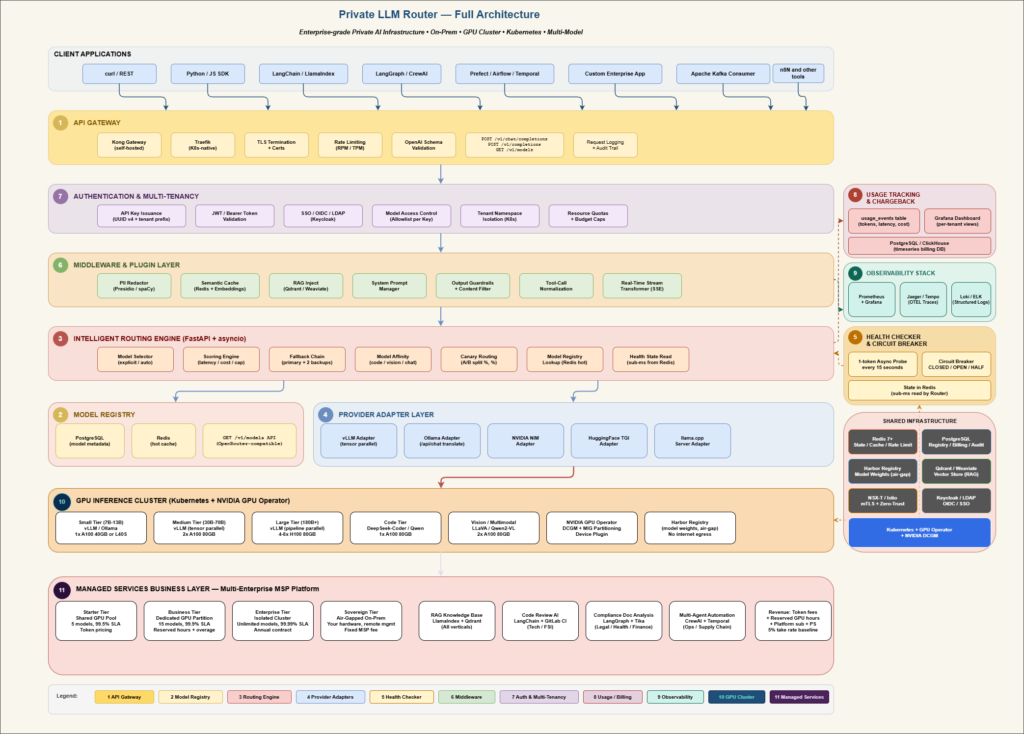
Core Components
- API Gateway
The API Gateway is the single entry point for all client traffic. It handles cross-cutting concerns before
requests even reach your routing logic.
- Kong Gateway (self-hosted): Best-in-class plugin ecosystem. Plugins for JWT, rate limiting,
request transformation, and Prometheus metrics out of the box. - Traefik: Lightweight, Kubernetes-native. Excellent for dynamic routing via IngressRoutes. Lower
operational overhead than Kong. - NGINX + Lua: Maximum control for fine-grained request manipulation at wire speed.
Your gateway must expose an OpenAI-compatible endpoint so existing tooling (LangChain,
LlamaIndex, Cursor, etc.) works without code changes:

- Model Registry
The Model Registry is the source of truth for every model available in your private cluster. It stores
metadata, capabilities, pricing (cost-per-token), health status, and endpoint locations.
Schema example (PostgreSQL):
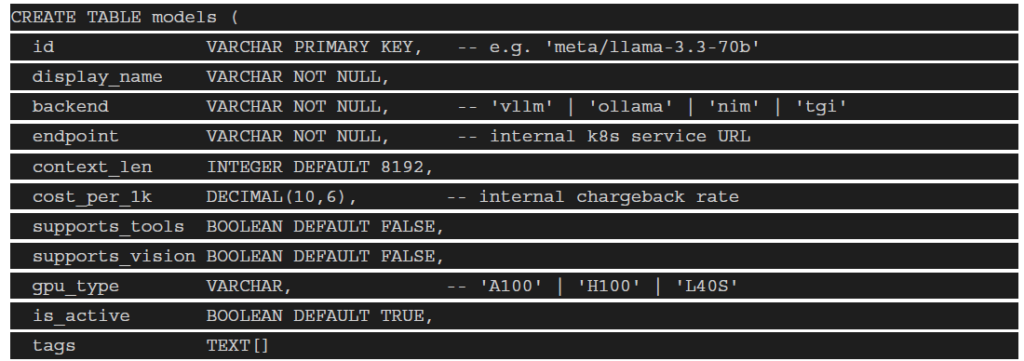
The registry should expose a REST API (GET /v1/models) returning the same JSON schema as
OpenRouter’s models endpoint — enabling zero-code integration with existing tooling.
3. Intelligent Routing Engine
This is the brain of the system. The routing engine receives a normalized request and decides which
backend model instance should serve it. It runs in milliseconds and consults multiple signals.
Routing logic (Python pseudocode):
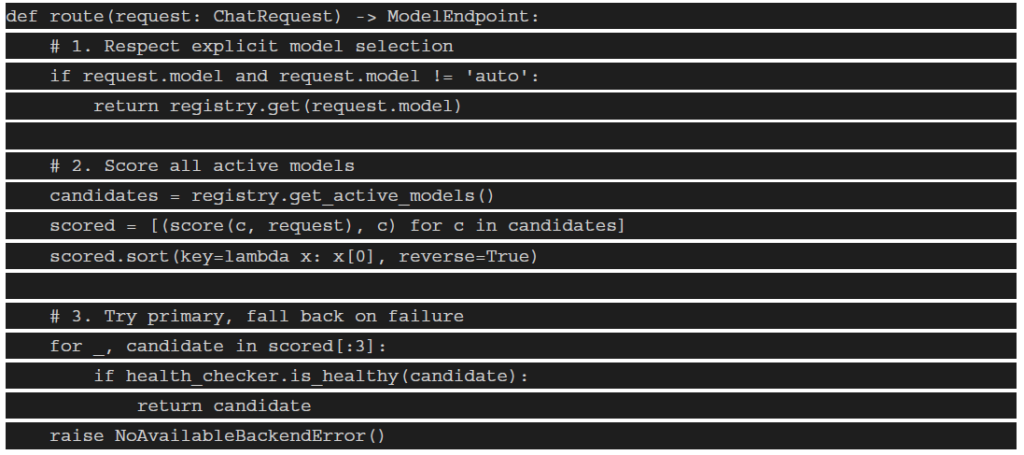
Scoring factors to implement:
- Latency score: Current p95 response time from Prometheus metrics
- Capacity score: (1 – GPU_util%) × weight — prefer underutilized GPUs
- Cost score: 1/cost_per_1k — prefer cheaper backends for simple tasks
- Capability score: Does this model support tools/vision if the request needs it
- Affinity score: Route coding tasks to code-specialized models (DeepSeek, Qwen-Coder)
4. Provider Adapter Layer
Each AI serving backend has a slightly different API contract. The adapter layer translates between your
unified OpenAI schema and each backend’s native format.


- Streaming: All adapters must normalize SSE (Server-Sent Events) delta format. Backends differ in
how they emit tokens. - Error mapping: Translate backend-specific errors (CUDA OOM, context exceeded) into standard
HTTP 429/500 codes. - Context enforcement: Reject requests exceeding a model’s max context before hitting the backend
to avoid wasted compute.
5. Health Checker & Circuit Breaker
Production inference endpoints fail. GPUs OOM. Pods restart. The health checker continuously probes
each backend and updates routing availability — preventing the router from sending traffic to degraded
instances.
Health check implementation:
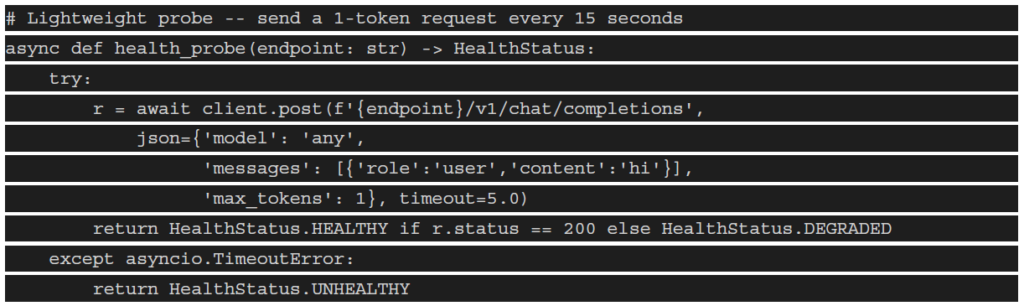
Store health state in Redis for sub-millisecond routing decisions. Never query the database during the hot
routing path.
6. Middleware & Plugin Layer
One of OpenRouter’s most powerful features is its middleware — capabilities layered on top of any model
without changing the model itself. In your private router, this is how you extend all models uniformly.
Middleware pipeline (request flow):
Incoming Request -> [PII Scan] -> [Cache Check] -> [RAG Inject] -> Backend
Backend Response -> [Guardrails] -> [Cache Store] -> [Usage Log] -> Client
Priority middleware to implement first:
- Semantic Cache: Hash normalized prompts and cache embeddings in Redis. Return cached
responses for semantically similar queries — dramatic cost savings for repeated workflows. - PII Redactor: Scan prompts for credit cards, SSNs, emails, named entities using spaCy or Microsoft
Presidio before sending to any model. - System Prompt Manager: Allow teams to register named system prompts centrally. Teams
reference them by ID rather than duplicating 2000-token prompts in every request.
7. Authentication & Multi-Tenancy
Enterprise deployments serve multiple teams, projects, and cost centers. Your router must enforce
namespace isolation, per-tenant rate limits, and chargeback visibility.

8. Usage Tracking & Chargeback
Even when there’s no per-token dollar cost (you own the hardware), tracking usage is critical for capacity
planning, cost allocation, and abuse prevention.
Usage event schema (write on every completed request):

Expose a dashboard (Grafana or custom React UI) showing token consumption per team, model
utilization breakdown, cost allocation per project, P95/P99 latency per model, and error rates.
9. Observability Stack
Without observability, you’re flying blind. The private router must emit metrics, traces, and logs that your
ops team can act on in real time.
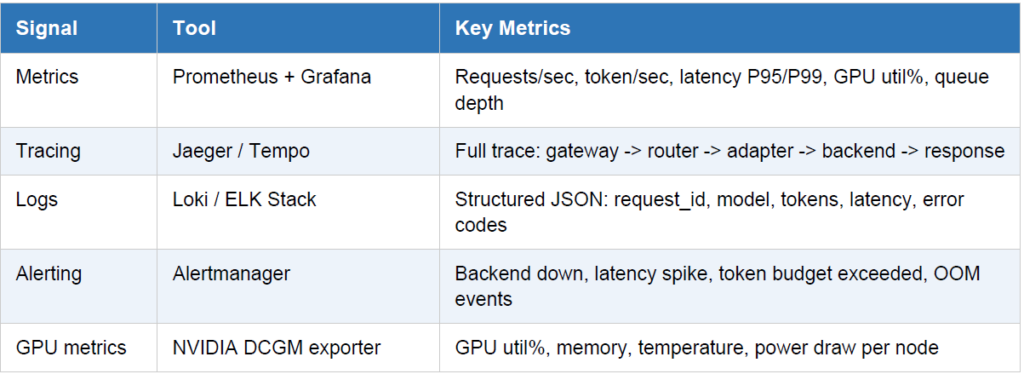
Instrument your router to emit an OpenTelemetry (OTEL) span for every hop. This gives you
end-to-end trace visibility from the client SDK all the way to the GPU kernel — invaluable for
debugging latency anomalies in multi-model workflows.
10. GPU Inference Cluster
The compute layer is where the actual inference happens. On a Kubernetes private cluster with NVIDIA
GPUs, your serving setup typically looks like this:
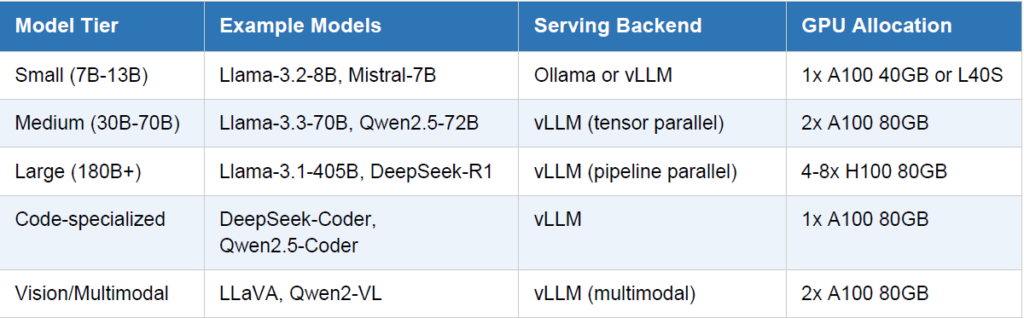
vLLM deployment example (Kubernetes manifest):

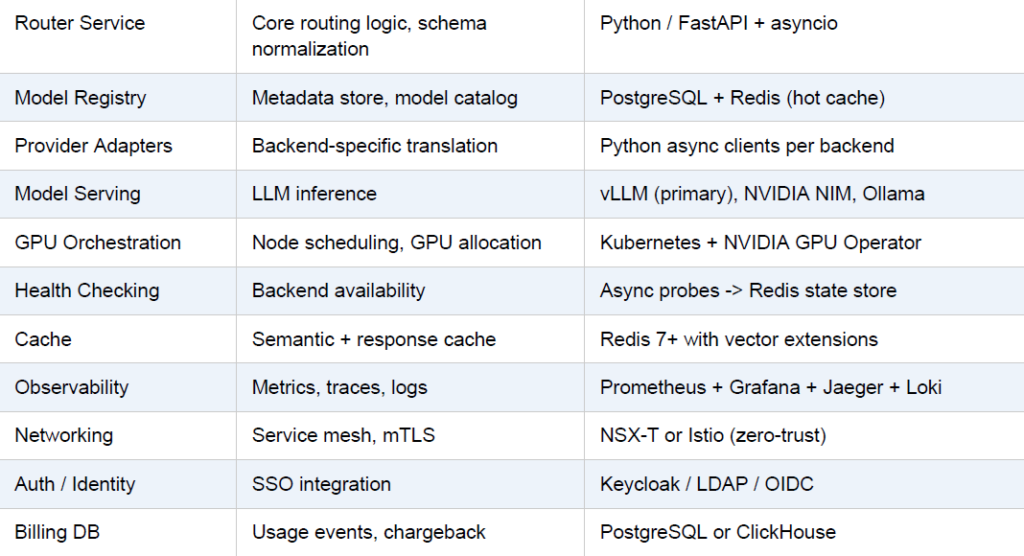
Recommended Tech Stack Summary

Security Considerations
A private router is security-critical infrastructure. It sits between all your AI workloads and your GPU
compute. These considerations are non-negotiable:
- mTLS everywhere: Use mutual TLS between the gateway, router, and all backend adapters. NSX-T
micro-segmentation or Istio service mesh can enforce this at the platform level. - No prompt logging by default: Log token counts and metadata, not prompt content. Make full
prompt logging an explicit opt-in with appropriate data governance controls. - Model isolation: Each model deployment runs in its own namespace with NetworkPolicy rules.
Cross-namespace traffic is denied unless explicitly allowed. - GPU node hardening: Disable SSH on GPU nodes. All access through Kubernetes API + RBAC
only. Patch CUDA drivers on a regular schedule. - API key rotation: Implement automatic key rotation policies. Support emergency revocation.
- Egress control: Firewall rules ensuring model inference nodes have zero internet egress. Model
weights pulled from internal artifact registry (Harbor), not Hugging Face directly.
Business Opportunity: Managed Private AI Router as a Service
Once you have built and battle-tested a private LLM router for your own organization, you have something genuinely rare — a production-grade, enterprise-hardened AI infrastructure platform. That is the foundation for a high-value managed service business serving multiple enterprise clients simultaneously.
Think of it as becoming the private OpenRouter for your industry vertical or region: hosting, operating,
and continuously improving the routing layer so enterprises don’t have to build it themselves. This section outlines the business model, service tiers, orchestration use cases, and the multi-tenant architecture that makes it commercially viable.
MARKET: Market Context
Enterprises want sovereign AI but lack the platform engineering talent to build it. Managed
service providers who can offer a turnkey private LLM router — with SLAs, compliance
assurances, and onboarding support — can command significant contract values while operating
shared GPU infrastructure at scale.
- The Managed Service Model
The core value proposition is simple: you operate the complexity so your enterprise clients don’t have to.
Each client gets a logically isolated tenant on your shared (or dedicated) GPU infrastructure, accessed
through their own private API endpoint and API keys, with full data isolation guarantees.
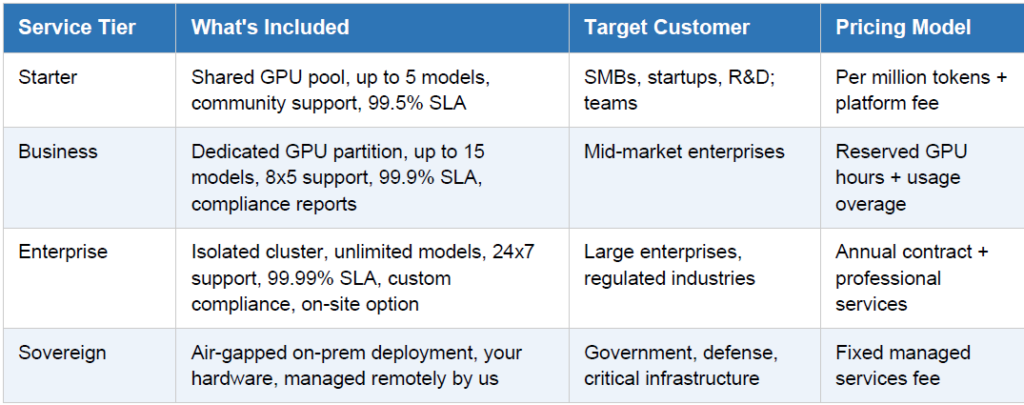
2. Multi-Enterprise Architecture
The key architectural challenge for a managed service is strong multi-tenant isolation while still sharing the expensive GPU compute efficiently. Here is how the layers split between shared and dedicated:

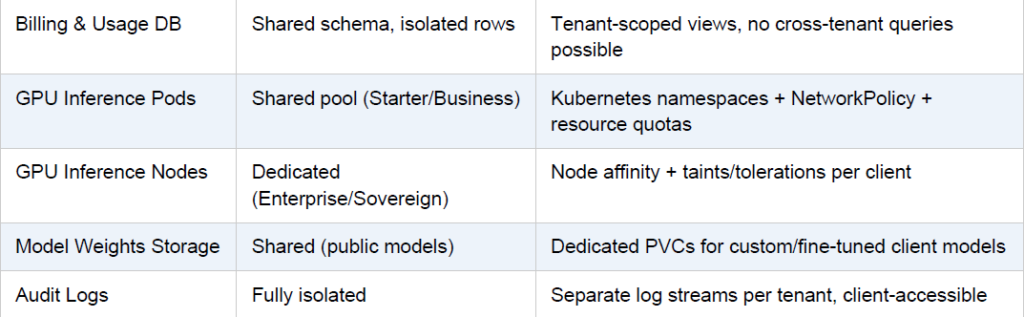
SECURITY: Data Guarantee
No enterprise client’s prompts, completions, or usage metadata are ever accessible to another
tenant. Enforce this at the database layer (row-level security), at the network layer
(NetworkPolicy), and contractually (DPA/BAA). Audit this separation quarterly.
3. Enterprise Use Cases Built on the Platform
Beyond raw API access, the real managed service value comes from helping enterprises build production
AI workflows on top of your router using orchestration tools. Below are the highest-value use cases by
industry vertical:
3a. RAG-Powered Knowledge Bases (All Verticals)
Every enterprise has unstructured document repositories — SharePoint, Confluence, internal wikis, PDF
archives. A managed RAG pipeline built on your router lets employees query this knowledge in natural
language without any data leaving the corporate perimeter.
Orchestration stack:
- LlamaIndex or LangChain: Document ingestion, chunking, and retrieval pipeline
- Qdrant or Weaviate (self-hosted): Private vector store for embeddings
- Your router: Serves both the embedding model and the generation model via one API
- Apache Airflow: Scheduled re-ingestion as documents are updated
3b. Code Review & Developer Assist (Technology / FSI)
Route coding tasks automatically to code-specialized models (DeepSeek-Coder, Qwen2.5-Coder) while
keeping all proprietary source code within the enterprise network. Integrate directly into GitLab CI/CD or
GitHub Enterprise via a webhook adapter.
Orchestration stack:
- GitLab CI/CD webhooks: Trigger reviews on merge request events
- Your router (model affinity tag: ‘code’): Automatically routes to best code model
- Prefect or Temporal: Workflow orchestration for multi-step review pipelines
- Redis pub/sub: Async result delivery back to the developer’s IDE
3c. Compliance Document Analysis (Legal / Healthcare / Finance)
Regulated enterprises need to analyze contracts, medical records, and financial filings without sending
sensitive documents to public APIs. A managed document intelligence pipeline on your router provides
this with full audit trails.
Orchestration stack:
- Apache Tika or Unstructured.io: Document parsing and normalization
- Your router middleware (PII redactor enabled): Auto-scrub before model sees data
- LangGraph: Multi-step reasoning workflows — extract, classify, summarize, flag
- PostgreSQL: Store structured outputs for downstream reporting and audit
3d. Multi-Agent Automation (Operations / Supply Chain)
Enterprises are moving beyond single-turn Q&A; to autonomous agents that can plan, tool-call, and
execute multi-step workflows. Your router becomes the inference backbone for agent frameworks that
need reliable, fast, private LLM access.
Orchestration stack:
- LangGraph or CrewAI: Multi-agent coordination (planner, executor, critic agents)
- Your router: Routes each agent’s LLM call to the optimal model — fast model for planning, powerful
model for reasoning - Temporal or Prefect: Durable execution, retry logic, and human-in-the-loop approval steps
- Apache Kafka: Event streaming between agents in high-throughput pipelines
3e. Customer-Facing AI Products (Retail / Telecom / BFSI)
Enterprises building their own AI-powered products (chatbots, copilots, recommendation engines) need a
stable, SLA-backed inference API. Your managed router becomes their internal ‘model provider’ —
shielding their product teams from infrastructure complexity.
Orchestration stack:
- Your router API: The only LLM endpoint their product team integrates
- Redis semantic cache: Cache common customer query patterns — dramatically reduces
per-session cost - Grafana dashboards (tenant-scoped): Product team can monitor their own usage and latency
- Canary routing: A/B test new models on 5% of traffic before full rollout
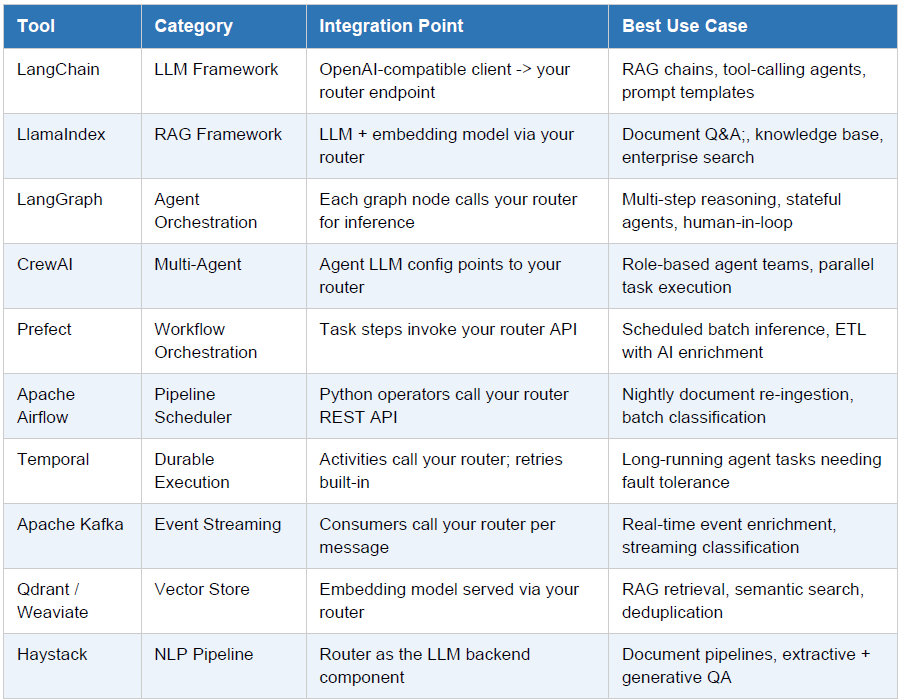
4. Orchestration Tools Integration Matrix
Below is a reference matrix of orchestration tools and how they integrate with your managed router
platform:
5. Revenue Model & Unit Economics
The managed service business model benefits from significant operating leverage — GPU infrastructure is
the primary cost, and it becomes more efficient as utilization increases across tenants.


Conclusion
Building a private LLM router is a significant but highly leveraged infrastructure investment. Once
deployed, it becomes the foundation for every AI-powered application in your organization — and
potentially for dozens of enterprise clients if you choose to operate it as a managed service.
The core insight from OpenRouter is powerful: abstract away the chaos of heterogeneous AI backends
behind a single, familiar API. The same principle applies at enterprise scale on private hardware — and
extends further into a commercial business model when you operate this platform for others.
Whether you are solving your own organization’s AI infrastructure problem or building a managed service
business around it, the architecture is the same. The difference is in how you slice tenancy, price the
service, and build the enterprise integrations that create lasting value.
vCloud Director: NSX-V to NSX-T Migration Part-2

CUCM AXL API – Bulk Logout of Extension Mobility Profile Using Python
AlgoSec – NSPM Solution Quick Review
About Author
abhishek
Expert in Network, Virtualization and Security field in On-Prem and Public Cloud. Passionate about new technology and consult the best solution to business organisation.Previously served Networkershome, EMC2, Cisco, VMware and Arista in different fields of Engineering, TAC, Consulting, Designing and Training. Certification : CCIE#48639, VCIX DCV and NV, Aviatrix Multi Cloud, SD-WAN Specialist, Palo Alto PCNSE, Amazon Cloud, Docker Certified Engineer. LinkedIn : https://www.linkedin.com/in/abhishekkunal51/